2025年6月25日(水)に開催された「建築ビジュアライゼーションMeetUp第8弾」のイベント内のセッション「建築業界における画像生成AIの可能性について」についてご紹介します。
主催 :株式会社Too
協力 :スペースラボ株式会社 / iceberg theory holdings株式会社
株式会社ナカサアンドパートナーズ
協賛 :オートデスク株式会社
講師 :スペースラボ株式会社/iceberg theory holdings株式会社 代表取締役 柴原 誉幸 氏
登壇者紹介 & セミナー概要
登壇者紹介

スペースラボ株式会社の柴原です。本日はAIについてお話したいと思います。今回はスライド100枚を超える大作を用意しましたので、スピード感を持って進めていきます。飛ばしながら進めてしまう場面もあるかと思いますが、その点はあまり気にせず聞いていただければと思います。
今日のテーマは「建築業界における画像生成AIの可能性」についてです。私は普段からこの技術を実際に活用している立場ですので、今日は皆さんに「明日からちょっと使ってみようかな」と思っていただけるような、実践的な内容をいくつか紹介していきます。

会社紹介

まず初めに、私たちの会社について簡単に紹介します。
スペースラボ株式会社は「ビジュアル体験を通じてビジネスの可能性を広げる」というビジョンのもと、言葉だけでは伝わりにくいものを視覚的に表現し、価値を提供している会社です。今年で創業17期目を迎えました。
事業領域は多岐にわたっており、もともとは建築ビジュアライゼーション、いわゆるパース制作からスタートしました。現在も月に数百枚単位で制作しており、主にデザイナーの方々をサポートする形で展開しています。それに加えて、広告用のCG制作や、メタバース領域におけるVR・ARコンテンツの開発なども手がけています。
また、少し変わったところでは「Cybaba(サイババ)」というグループ会社において、CG制作に特化したPCの製造・販売や、デジタルサイネージなどのハードウェアも扱っています。CGを“つくるため”と“見せるため”の環境を整えるというかたちの取り組みです。
さらに最近では、新たに「ドットハニカム」という会社を立ち上げました。これは施工業界向けに設計・施工のDX化を進めるための取り組みです。私たちだけでは現場のリアルがわからない部分もあるため、設計施工の会社、AI開発の会社、そして私たちの3社で共同設立した会社になります。

本日のテーマは画像生成AIについてですが、私たちは日頃から上の画像のようなビジュアルを制作している会社です。

内装業向けのパース制作も多く手がけているため、このような商業施設などの案件も数多く担当しています。
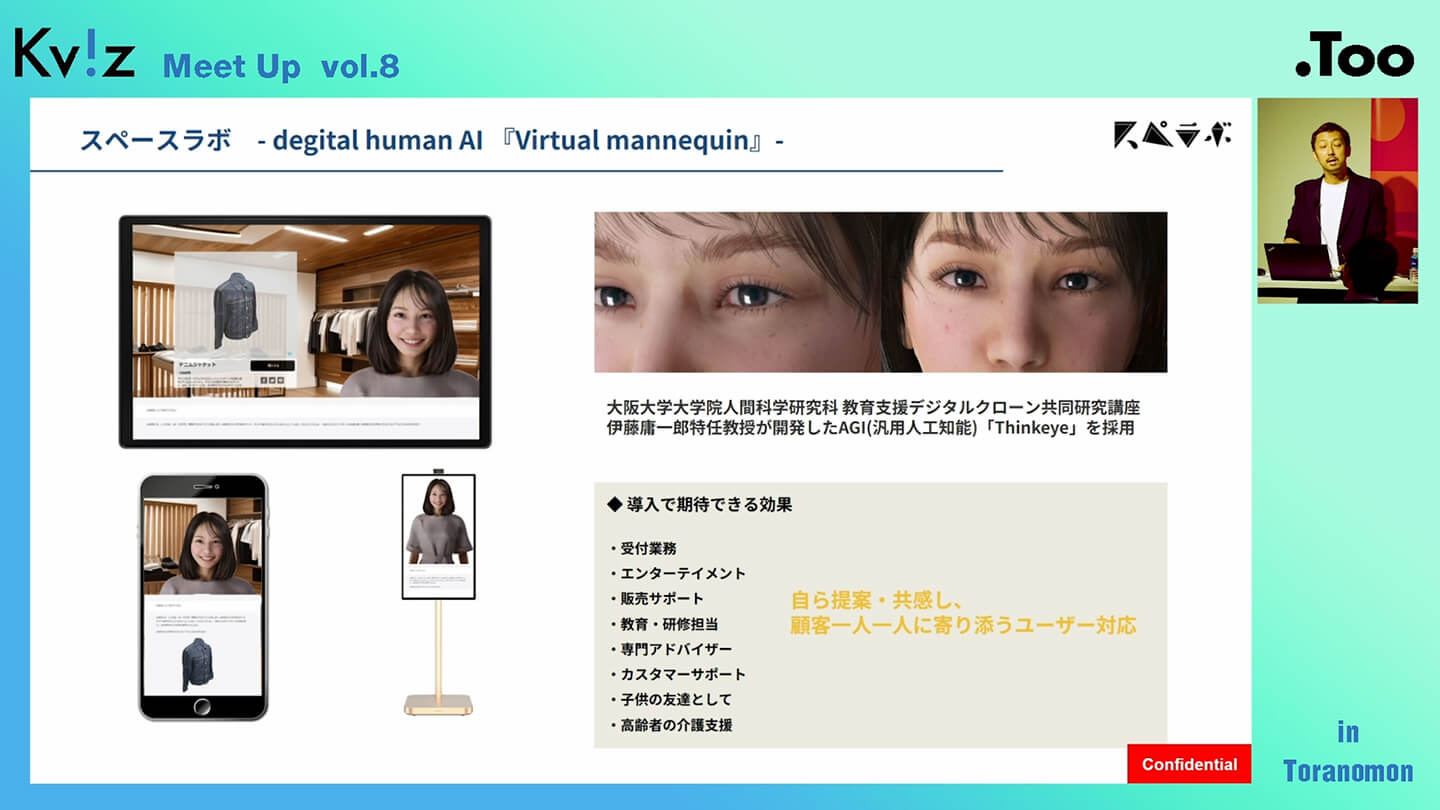
今回の取り組みのきっかけとなったのは、私たちが「デジタルクローンをメタバース上で表現しよう」というプロジェクトをスタートしたことでした。
その過程で、大阪大学の教授と連携しながらAI開発のビジネスに取り組む機会をいただき、AI技術について深く学ぶことができました。そうした経験を積み重ねて、現在の活動へとつながっています。なお、私たちが取り組んでいるAI技術は、一般的に知られているディープラーニングとは少し異なる、新しいアプローチを用いたものです。

今回のセミナーもそうした活動の一環で、企業向けに画像生成AIの導入支援も行っており、企業や個人が実際にAIを活用できるようサポートしています。
建築業界における画像生成AIの可能性について

さて、ここから本題に入ります。
まずは、「なぜ今、建築・内装業界でAIが注目されているのか?」という点についてですが、大きく3つの理由があると考えています。
注目理由①:人材不足

まず一つ目は、多くの業界で共通して語られる「人材不足」です。建築業界に限らず、社会全体で人手不足が深刻化しており、業務が追いつかないという現場の声をよく耳にします。特に若手人材の確保が難しく、将来的な人材構成に不安を感じている企業も少なくありません。
注目理由②:働き方改革

2つ目は、「働き方改革と業務の変化」です。そのため、業務効率化の必要性がかつてないほど高まっています。残業規制の影響もある中で、限られた時間内で成果を出す必要があります。その一方で、BIMなどの新しいツールが導入される中で、操作や活用に苦戦している企業も多く見られます。
また、近年は建築設計のプロセスにも「オンライン連携」や「デジタル前提の設計」など、新しい要件が次々に加わってきています。こうした背景から、いかに業務を効率化し、設計・施工の本質的な部分に集中できる環境を整えるかが大きな課題となっています。
注目理由③:若手世代との共通言語
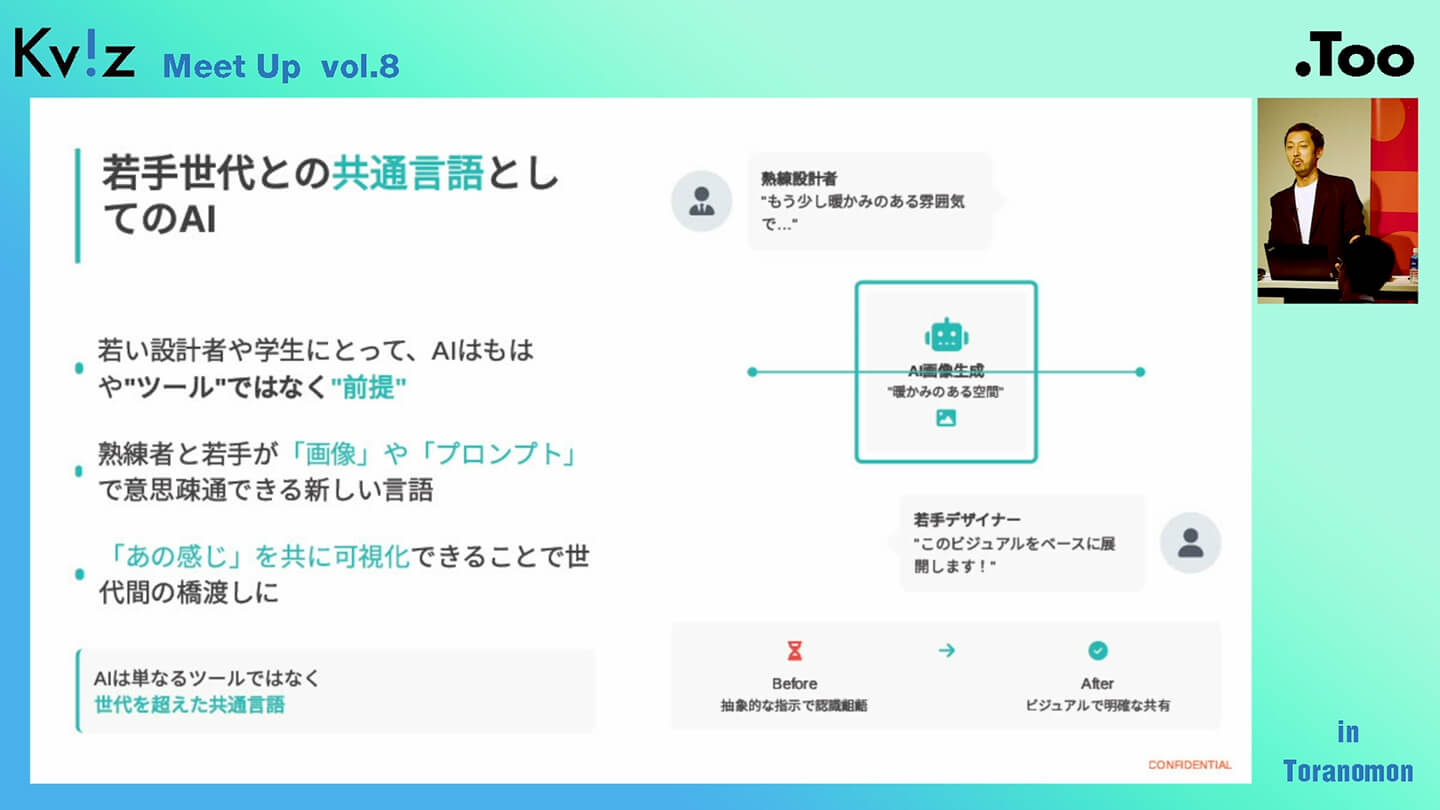
そして3つ目が、これからの若手世代との関わり方です。これまではSNSを使いこなす「SNS世代」が中心でしたが、今後はAIを当たり前のように使いこなす「AIネイティブ世代」が社会に入ってきます。
このような世代と共に働くためには、私たち自身もAIを理解し、活用できる状態であることが求められます。業務の中でAIを使うことが当たり前になる時代に向けて、社内の環境やコミュニケーションのスタイルも見直していく必要があるのです。
画像生成AIの導入効果

実際の統計データを見ても、建築分野においてAIを導入した企業では、初期段階から業務スピードが3倍から10倍程度向上するという結果が出ています。もちろんプロジェクトの内容にもよりますが、初速の生産性に大きなインパクトがあることがわかります。
また、もう一つ大きな課題として「デザイナー不足」が挙げられます。これに対してもAIの導入は効果的です。簡単な作業であれば、デザインの専門知識がない人でもAIを活用して一定レベルのアウトプットを出すことが可能になり、非デザイナーを業務の一部で“デザイナー的に”活用できるという点でも注目されています。
さらに、AIの導入によって「手戻り」や「確認作業」にかかるコストを削減できるという効果も期待されています。
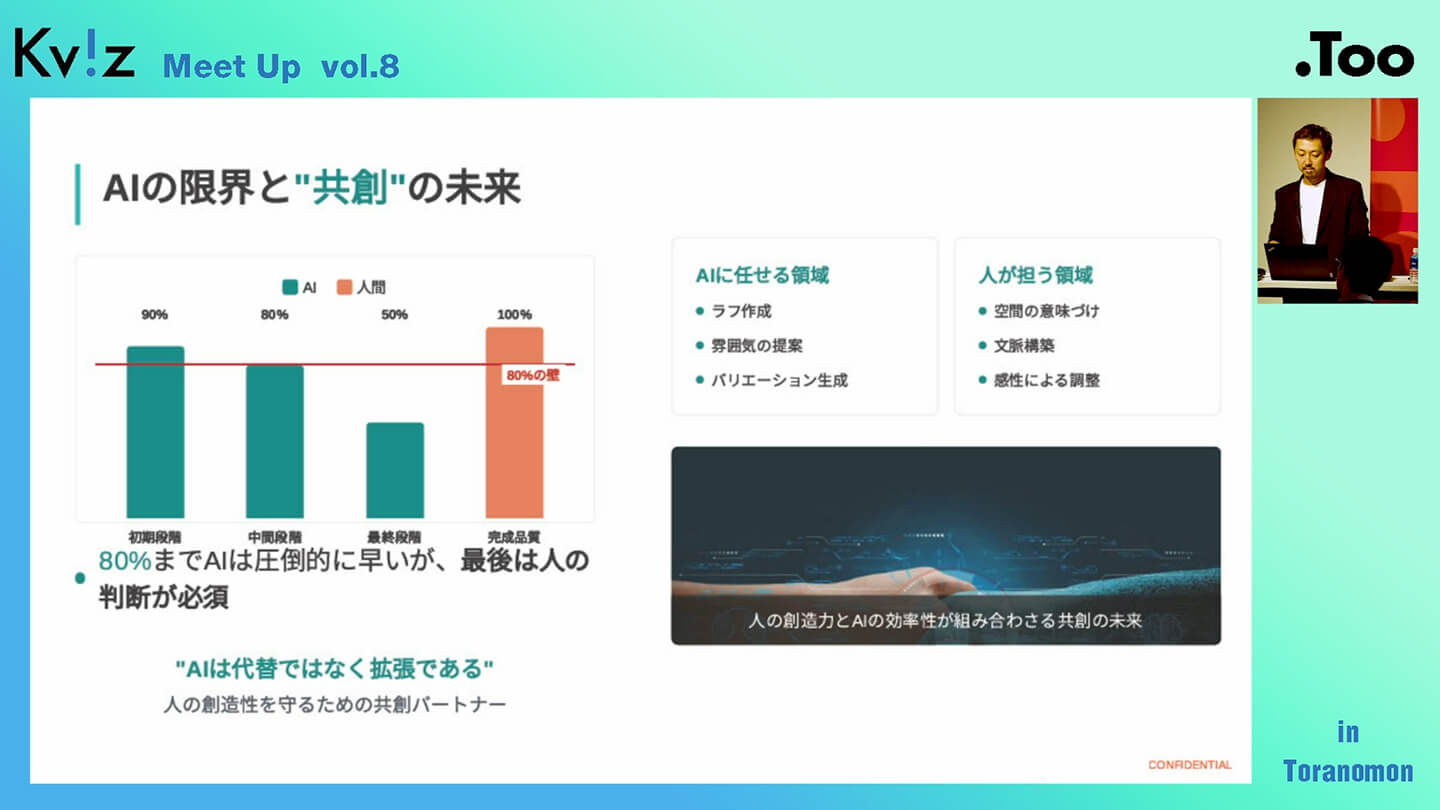
AIに対してよく聞かれるのが、「AIに仕事を奪われるのではないか」という不安の声です。日常的にAIに関わっている私としては、これはまったくの誤解だと思っています。
AIは「人間の仕事を“代替”するものではなく、“共創”のパートナー」です。AIの力を借りることで、人が本来注力すべきクリエイティブな業務や、価値の高い仕事に、より多くの時間とエネルギーを割けるようになります。こうした変化は、今後の働き方に大きな影響を与えていくはずです。

具体的な活用事例や導入のコツについては後ほど詳しく紹介しますが、ここではいくつか代表的なメリットを挙げておきます。
まず、打ち合わせの回数を減らせるという点は非常に大きな利点です。また、先ほども少し触れましたが、社内コンペや初期提案のスピードが大幅に向上することもポイントです。さらに、素材案を複数用意するような場面でも、画像生成AIを使えば短時間で簡単に作成できます。
こうした点を踏まえると、画像生成AIを導入する際は、最初からすべての業務に適用しようとするのではなく、まずはビジュアル検討のような限定的な用途から試してみるのが、社内に無理なく浸透させるコツだと感じています。
画像生成AIとは?
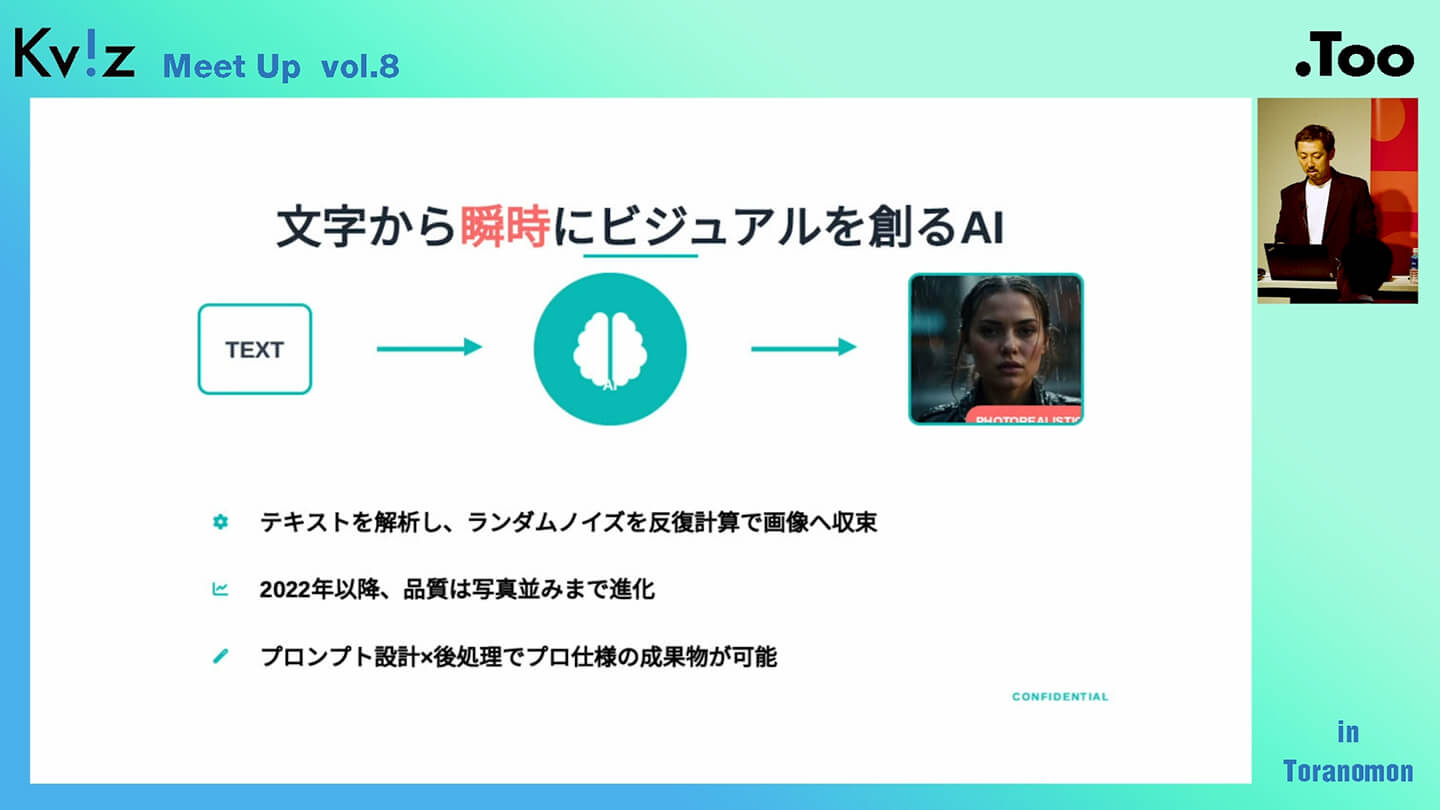
ここからは、少しマニアックな内容に踏み込んでいきたいと思います。まず画像生成AIについてですが、文字から瞬時にビジュアルを創るAIのことを指しています。
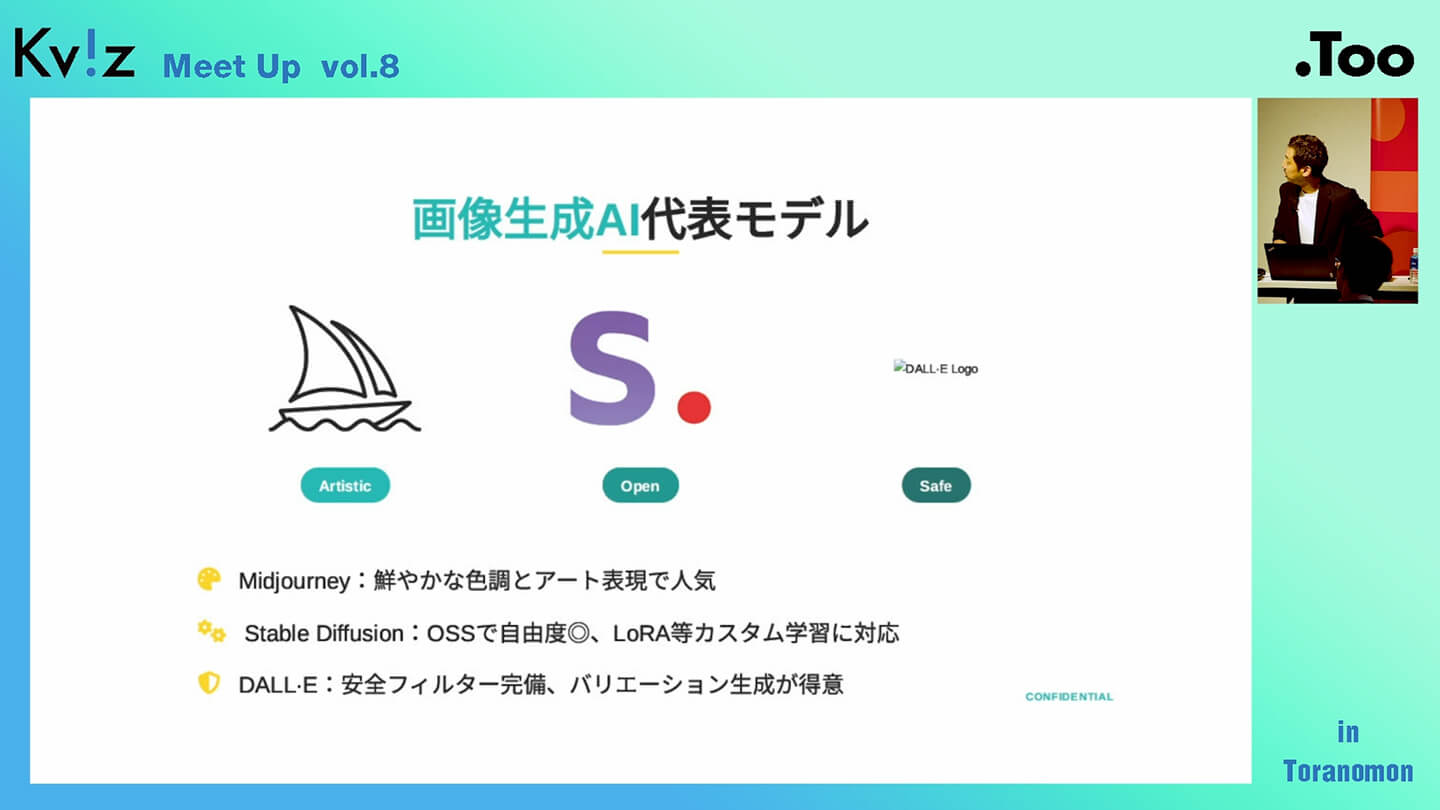
すでにご存じの方も多いかもしれませんが、画像生成AIの中でも特に広く使われているのが、『Midjourney』と『Stable Diffusion』、そして『DALL·E』の3つです。このあたりが、現在の主流と言える代表的なツールと言えます。

ここで、少し質問です。現在、世の中にどれくらいの「画像生成AIモデル」が存在しているかご存知でしょうか?

実は、世界には50種類以上の画像生成AIモデルが存在しています。ここで言う「モデル」とは、MidjourneyやStable Diffusionのような生成の仕組みそのものを指しており、サービスやアプリの数ではありません。
さらに、それぞれのベースモデルから派生した「ファミリーモデル」も多数存在します。たとえば、先ほど触れたStable Diffusionだけでも、複数のバリエーションやカスタマイズモデルが展開されているのが現状です。

現在では、こうした多様なモデルが市場を席巻しており、たとえば『Ideogram』や『Firefly』、『Leonardo』などが広く注目されています。中でも私が最近注目しているのが、『Google AI Studio』です。これらの新しい技術やサービスが、ものすごいスピードで画像生成AIの可能性を拡張し続けています。
体感としては、およそ2週間ごとに新たなアップデートが登場し、AI技術が次々と革新されているようなイメージです。特に画像生成AIに関しては、実際に触れている人でなければ、その変化や進化のスピードを実感するのは難しいと思います。
新機能の追加や使い勝手の向上など、アップデート内容が非常に速いサイクルで行われており、「しばらく触っていなかったら、もう別物のようになっていた」ということも珍しくありません。それだけ情報収集が追いつかないというのが、多くの人にとっての現実だと思います。私たちは、そうした急速な変化に対して、プロとして常に最新動向を把握し、実務に落とし込むことを意識しながら取り組んでいます。

AI画像生成モデル詳細

ここで、AI画像生成モデルを一部紹介します。MidjourneyやAdobe Firefly、Sora、Runway、Klingなどがあります。


現在、私たちが注目している画像生成AIモデルは7つあります。MidjourneyとDALL·E 3、Stable Diffusion XL、Adobe Firefly、そして、Kling、Imagen、FLUX AIといった最新のモデルです。
それぞれに異なる特徴や強みがあり、私たちはこの7つを重点的にリサーチし、活用の可能性を日々検証しています。

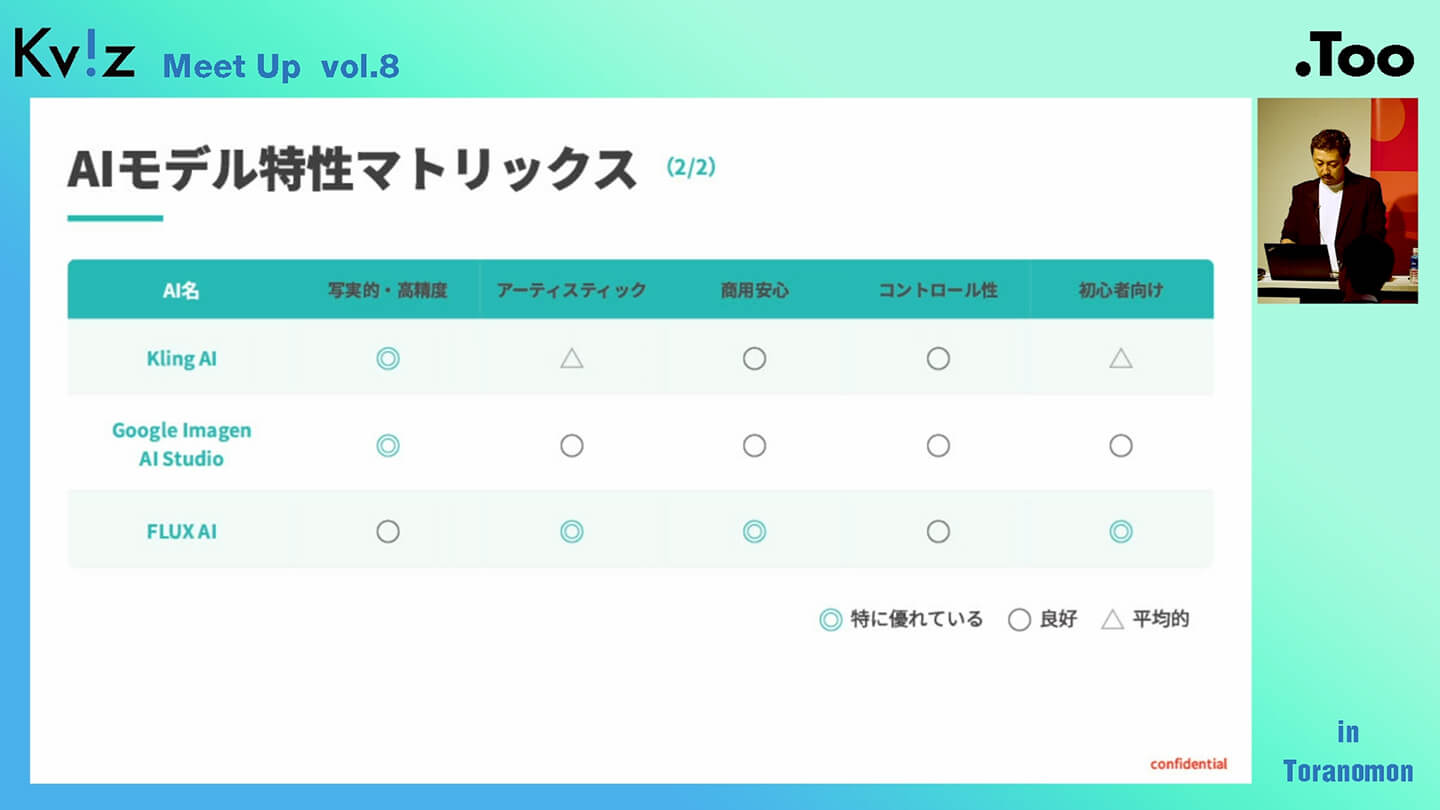
私たちの中では特定の評価軸に基づいた「AIモデル特性マトリックス」を用意しており、各画像生成AIモデルの特徴を整理しています。こちらについては、後ほど実際の画面をご覧いただきながら詳しく紹介する予定です。
今回は建築業界に関連した内容が中心ということで、特に注目しているのがFLUX AIです。建築・空間デザインとの親和性が高く、実務での活用においても非常に可能性を感じているモデルです。
画像生成AIの2つの利用形態

AIモデルが数多くある中で、実際に皆さんが触れているものには、大きく分けて2つのタイプのサービスがあります。
一つは、OpenAIのように「基盤モデル」を開発している企業が提供するもの。そしてもう一つは、その基盤モデルの上に独自のUIやUXを組み合わせて提供されているサービスです。これはChatGPTとOpenAIの関係と同じ構造で、画像生成AIも同様の仕組みになっています。
AI業界ではよくある話ですが、皆さんが気にされるのがコストの問題です。コスト面だけを見ると、モデルを直接開発・提供している企業のサービスを使う方が、一般的には安価になります。
というのも、他社がそのAIモデルをAPI経由で利用し、自社のUIやUXに組み込んでサービス化している場合、その分の開発・運用コストが価格に上乗せされるからです。つまり、間に入るレイヤーが多いほど、どうしても価格にも反映される構造になっています。

しかし、価格が高くなるからといって、それが必ずしも「悪い選択」というわけではありません。むしろ、UIやUXに優れたサービスは、使いやすさに特化しているという大きなメリットがあります。
たとえば、Stable Diffusionをベースにしたサービスでも、人物に特化したものや、建築ビジュアライゼーションに特化したものなど、用途ごとに最適化されているケースがあります。そのため、自分が何を目的に使うかによって、選ぶサービスは変わってくるのです。
特に初心者の方にとっては、多少コストが高くても、UI/UXがしっかり設計されているサービスを選んだ方が、操作にかかる時間や学習コストを大幅に削減できる可能性があります。結果として、時間という観点から見れば、むしろコストパフォーマンスが高い選択になることも十分にありえます。
ポイント①
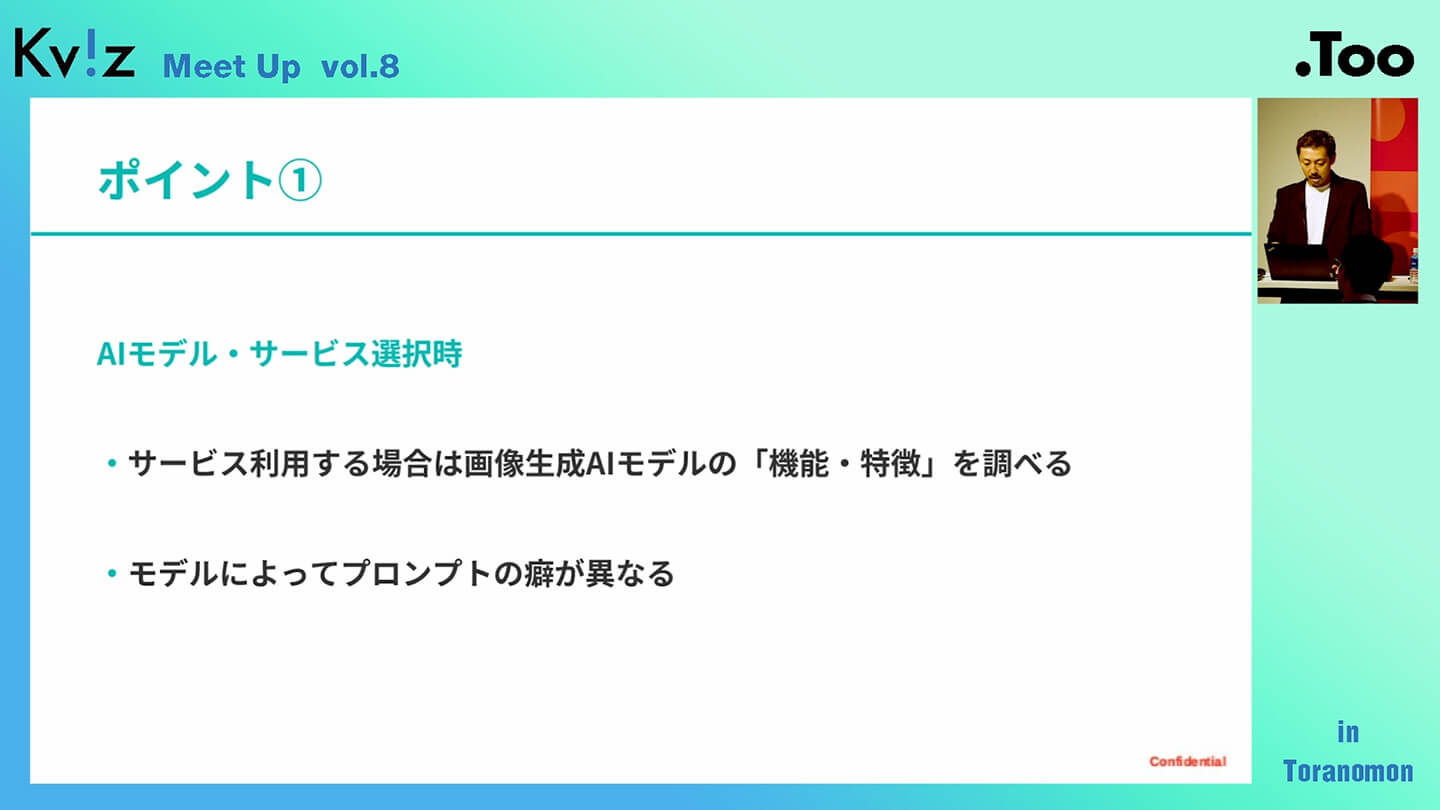
ここは非常に重要なポイントです。このあとも改めて触れますが、画像生成においてプロンプトの入力は非常に重要です。どのような言葉を使って指示を出すかによって、生成される画像のクオリティや方向性が大きく変わってきます。
実際には、利用するサービスによって採用されているAIモデルが異なっており、それぞれプロンプトの受け取り方や反応に特徴があります。たとえば、MidjourneyとStable Diffusionでは、同じプロンプトでも結果が大きく異なる場合があります。
そのため、自分が使っているサービスがどのAIモデルをベースにしているのかを一度調べたうえで、そのモデルに最適化されたプロンプトの書き方を意識することが大切です。これによって、より意図に沿った、効果的な画像生成が可能になります。

サービスの例として挙げられるのが、『Canva』や『Leonardo』などです。これらのサービスは、画像生成AIの機能を複合的に備えているだけでなく、UI/UXが非常に優れており、直感的に使いやすい点が特徴です。

AI導入における法的コンプライアンス対応についてよく質問をいただくのですが、私自身は法律の専門家ではないため、詳細な解説は控えさせていただきます。ただし、私たちも顧問弁護士と定期的に意見交換をしており、その中で参考にしている情報として、経済産業省が今年の初めに公開した「AI導入ガイドブック」があります。
このガイドブックでは、AI導入時のコンプライアンスやリスク管理に関する基本的な考え方や、企業が導入を検討する際に留意すべき点がまとめられています。行政機関が作成した資料なので、内容の解釈がやや難解な部分もありますが、今のようにコンプライアンスへの関心が高まっている中で、自社がどのようなサービスを使い、何を扱うのかを検討する際の参考資料として非常に有用です。
もちろん、最終的には自社の法務部門や顧問弁護士と相談しながら、慎重に進めていくことが重要です。
また、具体的なサービスを巡っては注意すべき点もあります。たとえば、Midjourneyについては「商用利用可」と明記されていますが、現在、著作権を巡る訴訟が進行中です。ここで混同しがちなのが、「商用利用が可能」ということと「著作権上の問題がない」ということはまったく別の話だという点です。
商用化できるからといって、生成されたコンテンツに著作権上のリスクがないとは限りません。このあたりの違いをしっかりと理解することが求められます。

【実践】スペースラボのおすすめAIを活用した建築ビジュアライゼーション

ここからは、実際のスペースラボでのAI活用について紹介していきます。

私たちが日常的に使用しているのは、先ほども紹介したこれら7つの画像生成AIです。私たちはプロフェッショナルとしてAIを目的に応じて使い分けているため、一つのツールに依存するのではなく、複数のモデルを組み合わせて活用しています。
なぜ使い分ける必要があるのかというと、それぞれのAIモデルには得意・不得意があるからです。たとえば、建物の外観を得意とするモデルもあれば、植物表現に強いもの、人物生成に特化しているもの、インテリアのグラフィックや質感に強いものなど、性能に明確な違いがあります。
つまり、建築ビジュアライゼーションにおいて「AIを使う」と言っても、何でも一つのツールで済ませられるわけではなく、目的に応じた最適なAIを選んで使うことが重要なのです。私たちはそうした前提のもと、状況に応じて最も適したAIモデルを選択しながら、より完成度の高いビジュアル表現を実現しています。
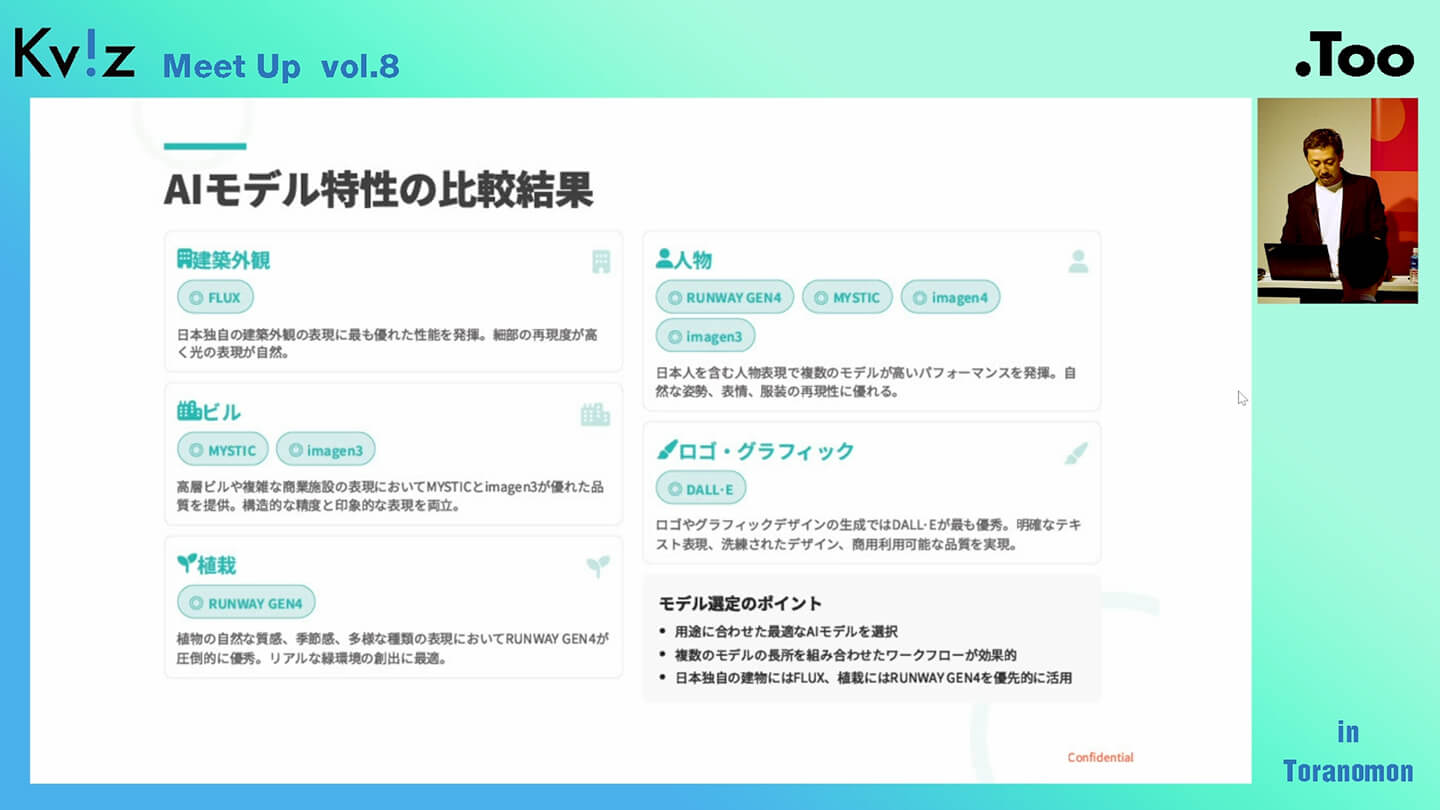
ここからは、私たちの実務経験に基づいた主観ではありますが、用途別におすすめの画像生成AIモデルをご紹介します。
まず、建築の外観に関しては、FLUX AIが非常に得意です。ビルのような大規模構造物には、MysticやImagen 3が適しており、自然なスケール感やディテールを再現できます。植栽やグリーンの表現については、Runwayが高い表現力を持っています。また、人物の生成においても、Runwayに加えてMystic、Imagen 3、そしてImagen 4が優れた結果を出してくれます。一方で、ロゴやグラフィックデザインの領域では、DALL·Eが非常に使いやすく、特にシンプルでわかりやすい構成を求める場合に効果的です。
DALL·Eに関連して、プロンプト入力に不安がある方には「ChatGPT-4o」がおすすめです。というのも、ChatGPT-4oは非常に高い言語理解力を持っているため、ユーザーの意図を自然に読み取ってくれます。会話形式でやり取りしながら、丁寧にビジュアルを生成してくれるため、プロンプトに慣れていない方でも直感的に望むイメージに近づけることが可能です。「どんなビジュアルを作りたいのか」という目的に対して、ストレスなく試せる環境としては、ChatGPT-4oは非常に優れたツールと言えます。
実践活用と工夫

ここからは、実際の画像生成AIの「サービス」についてご紹介します。これまでは主にAIモデルそのものについて触れてきましたが、サービスとしておすすめしたいのが、画面左下に挙げているProject DreamとRendair、Freepikの3つのツールです。
まず、Project DreamとRendairは、建築に特化した画像生成AIサービスで、UI/UXの面でも非常に使いやすく設計されています。建物の生成や空間演出に関する機能が充実しており、建築ビジュアライゼーションとの相性がとても良いのが特徴です。
もう一つ、Freepikは画像生成に関するさまざまな補助機能が揃っており、幅広い用途に対応できる汎用性の高いツールです。この3つを押さえておけば、「画像生成AIで何か試してみたい」という方にとって、非常に良いスタートになるはずです。
ただし、ここで一つ気をつけたい点があります。それは、「日本人を生成するのが難しい」という問題です。たとえば、建物の生成に関しては先ほどの3つのサービスでも非常に優れた成果が得られますが、人物を入れようとすると、出力されるのは外国人のビジュアルが中心です。日本人らしい顔や雰囲気を求める場合には、なかなか思い通りにいきません。
そのため、私たちは用途によって使い分けをしています。建物部分まではAIで生成し、人物に関しては後からPhotoshopなどで追加・調整するという手法をとっています。今のところはそうした手間が必要ですが、これは技術の進化とともに解決されていく可能性が高いと見ています。
もちろん、すべての工程をAIだけで完結させることも不可能ではありません。ただし現時点では、「得意な部分はAIに任せ、苦手な部分は人の手で補う」という考え方のほうが、より現実的で実用的だと感じています。
ポイント②
ここからの話は、私自身が普段から強く感じていることでもあります。人物の生成に関しては現状ではまだ不自由な点が多いため、Photoshopなどで処理してしまった方が効率的だと考えています。
ただし、今回の技術進展の中で非常に良い点もあります。それは、これまで「添景素材」と呼ばれていた人物素材が、画像生成AIによって自分で生成できるようになったという点です。これまではストックフォトや素材集に頼っていた部分も、AIを活用すれば柔軟に対応できるようになってきています。その点においては、画像生成AIを積極的に活用するメリットは大きいと思います。
また、「CG制作はプロンプト」と書くと少し分かりにくく感じるかもしれませんが、これは実務で画像生成AIを使っているとよく直面するポイントです。たとえばポスターのようなグラフィックデザインをAIで作ろうとする場合、「タイトルは上、サブタイトルは中央に配置」など、文字や要素の位置を細かく指定しなければならないケースが多々あります。
しかし、これをプロンプトだけで正確に伝えるのは非常に大変です。構成を言葉で定義するには、かなりの工夫や試行錯誤が必要になります。一方、CGであれば、椅子はここ、壁は奥、照明は天井といったように、すでにビジュアルとして構成が定まっているので、それをもとに画像生成AIと組み合わせることで、より意図通りのアウトプットが得やすくなります。
つまり、ゼロからプロンプトだけで建築ビジュアライゼーションを作るのは難易度が高く、「言葉の壁」にぶつかることが多いというのが実情です。だからこそ、あらかじめCGで構成を決めておき、そのうえで画像生成AIと組み合わせて使うという考え方が現実的です。
私は、CG制作そのものを「ビジュアルプロンプト」だと考えて使ってみることをおすすめします。言葉では伝えにくい構図やニュアンスを、CGによって視覚的に伝えること、それが今のAI時代において非常に有効なアプローチだと思います。
Magnificで高精細化
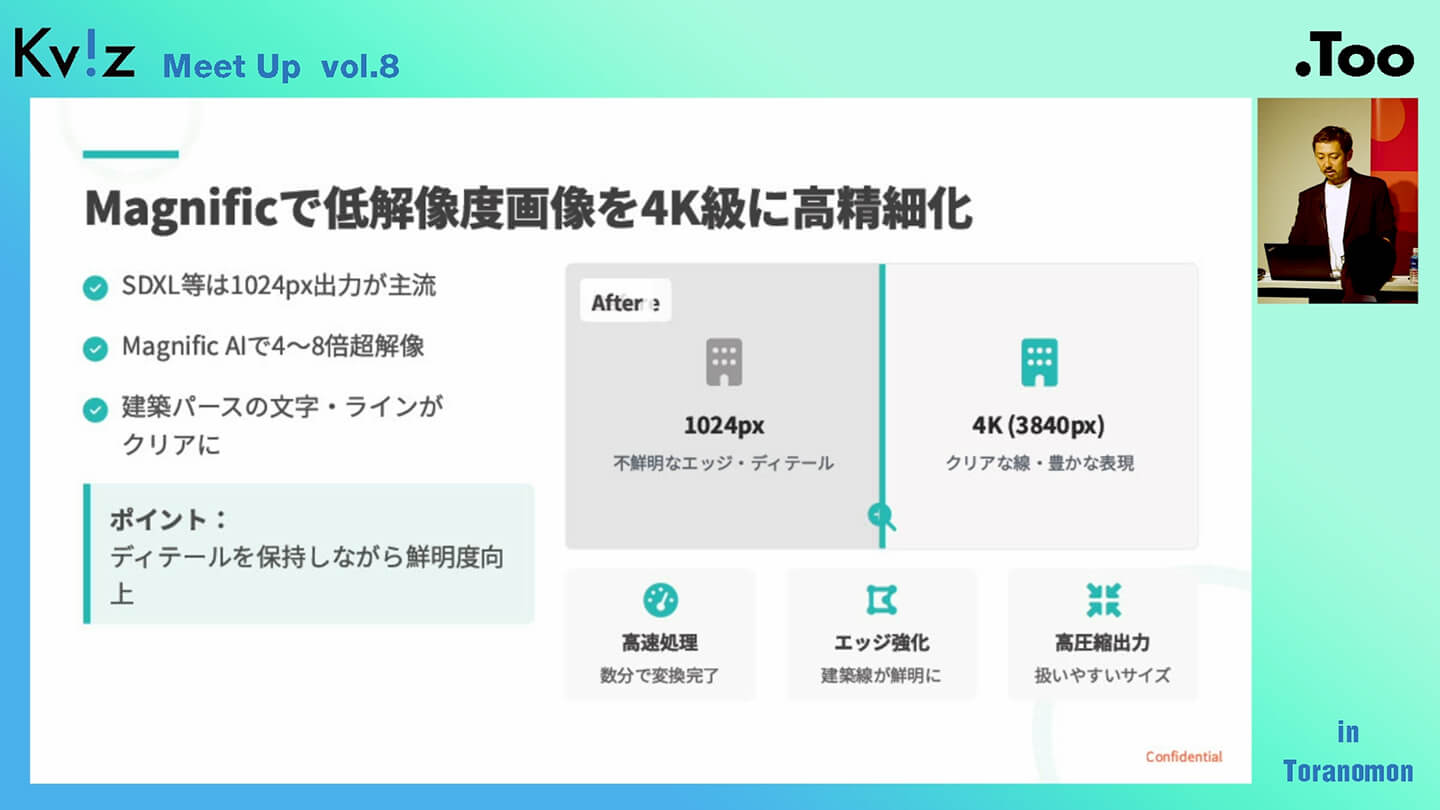
最後に、実務で非常に重宝しているツールを一つ紹介します。あまり知られたくないくらい便利なサービスなのですが、『Magnific(マグニフィック)』というAIツールです。
画像生成AIでは、各サービスごとに出力できる解像度に制限があるのが一般的です。画面で見る分には問題ないように思えても、実際に印刷したり大きなサイズで出力したりすると、「思ったより粗かった」「ディテールが足りなかった」といった問題が起こりがちです。
Magnificは、そうした画像を高解像度に拡大しつつ、ディテールを保ったまま鮮明に仕上げてくれるAIツールです。月額コストはやや高めではあるものの、実務レベルでは十分その価値があると感じています。8K程度の高解像度出力にも対応しており、大判のビジュアル制作にも対応可能です。
特に優れているのは、ディテールを保持しながら鮮明度を向上できる点と、処理速度の速さです。こうした点から、プロフェッショナル用途での活用には非常に適しています。
ここで重要なのは、「無料の高解像度化ツール」との違いです。無料のツールでは、ただ画像を引き伸ばしてピクセル数を増やすだけのものも多く、結果として画質がぼやけたり、粗くなってしまうケースがあります。Magnificは、AIが構造を理解したうえで画質を再構築してくれるため、精度がまったく異なります。ですので、ここは必要経費だと感じています。
日本人生成の課題と解決策

人物生成AIに関しては、先ほども少し触れましたが、RunwayやImagen、Mysticといったツールが非常に優れています。これらを使えば、建築ビジュアライゼーションやCGパースに組み込む人物素材を、高品質に生成することが可能です。
また、多くのサービスでは、背景の自動切り抜き機能が備わっており、生成後すぐに人物だけを抽出することもできます。さらに、ポーズの指定もある程度対応しているため、目的に合わせて調整することで、より自然な配置や表現が可能になります。
ここでポイントになるのが、プロンプトの工夫です。私自身、プロンプトの作成にはChatGPTを活用しています。というのも、ChatGPTは非常に柔軟で賢く、こちらが描きたいイメージや人物の特徴を伝えると、それに合わせて適切な英語のプロンプトを生成してくれるからです。
使い方としては、たとえば「このAIモデルで、こういう雰囲気の人物をつくりたい」という要望を伝えると、ChatGPTがそのモデルに適した形式でプロンプトを提案してくれます。それをそのまま画像生成AIに入力すれば、精度の高い出力が短時間で得られるので、非常に効率的です。
このように、AI同士を組み合わせることで、プロンプトの質を高め、画像生成の成果をより意図に近づけることができます。プロンプト設計に自信がない方でも、こうしたアプローチならスムーズに始められるのではないでしょうか。
AI活用ベストプラクティス ワークフロー

工程としては少し重なる部分もありますが、私たちが実際に行っている画像生成のステップを紹介します。
まず最初に、CGで建物の外形を作成します。その後、FLUX AIでベースとなる建築ビジュアルを生成し、Mysticを使って植栽などの自然要素を追加します。続いて、Imagenで人物を入れ込み、Magnificで画像全体の解像度をアップスケールし、最後にPhotoshopで細かな補正や仕上げを行うという流れです。
こう聞くと、「多くのAIツールを使っていて、手間がかかりそう」と思うかもしれませんが、実際はこの方法の方が圧倒的に早く、高品質なビジュアルを効率よく作れます。もちろん、これはあくまで私たちのワークフローであって、用途や案件の内容によって最適なやり方は変わります。すべてにこの手順が当てはまるわけではありませんが、複数のAIを連携させることで、手作業に頼らずとも高い完成度を実現できるのは、AIを活用する上での大きなメリットです。
実際の制作プロセス
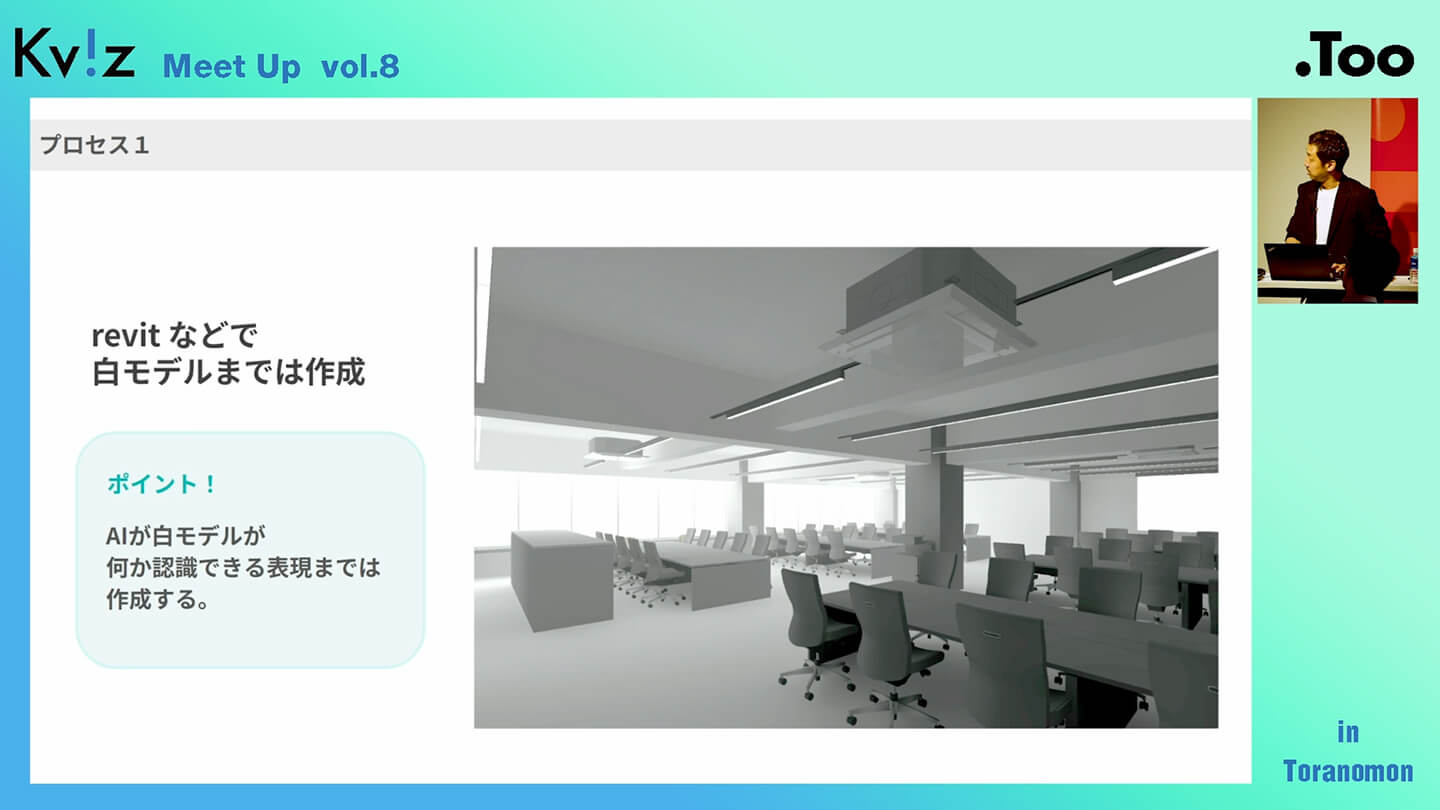
ここからは、実際の制作プロセスについてご紹介します。
私たちは、まずRevitなどのBIMソフトに組み込まれているモデルデータを活用するところから始めます。ここで重要なのは、無理に一からモデリングをするのではなく、プリセットとして用意されているモデルをうまく組み合わせて使うという点です。
つまり、「そのオブジェクトが何であるか」が明確に伝わるレベルで並べておけば、それだけで十分な表現になることが多いのです。詳細なディテールまでつくり込むというよりも、ビジュアルとして伝わる最低限の情報が揃っていればOKという考え方で、効率的に制作を進めています。

前述したように、私たちはChatGPTを活用してプロンプトを作成しています。まずは、「ベースとなるプロンプト」と「実際にAIに指示したい具体的な内容」の2つを整理し、それをChatGPTに伝えます。すると、AIがそれらを組み合わせて、最適なプロンプト文に仕上げてくれます。
ここでのポイントは、最終的に「英語でプロンプトを入力すること」です。というのも、多くの画像生成AIは英語を前提に設計されているため、日本語では意図がうまく伝わらなかったり、出力結果が不安定になったりすることがあります。そのため、最終的にプロンプトを英語で整えるプロセスは非常に重要です。

先ほど紹介した元の画像に対して、FLUXを使って画像生成を行うと、一度の出力でここまで仕上がります。
このとき使用したプロンプトは、「デザイン事務所が使うようなオフィスにしてほしい」といった内容です。そのため、壁面やインテリアにグラフィック要素が追加されたり、全体に洗練された印象のある空間に仕上がっています。
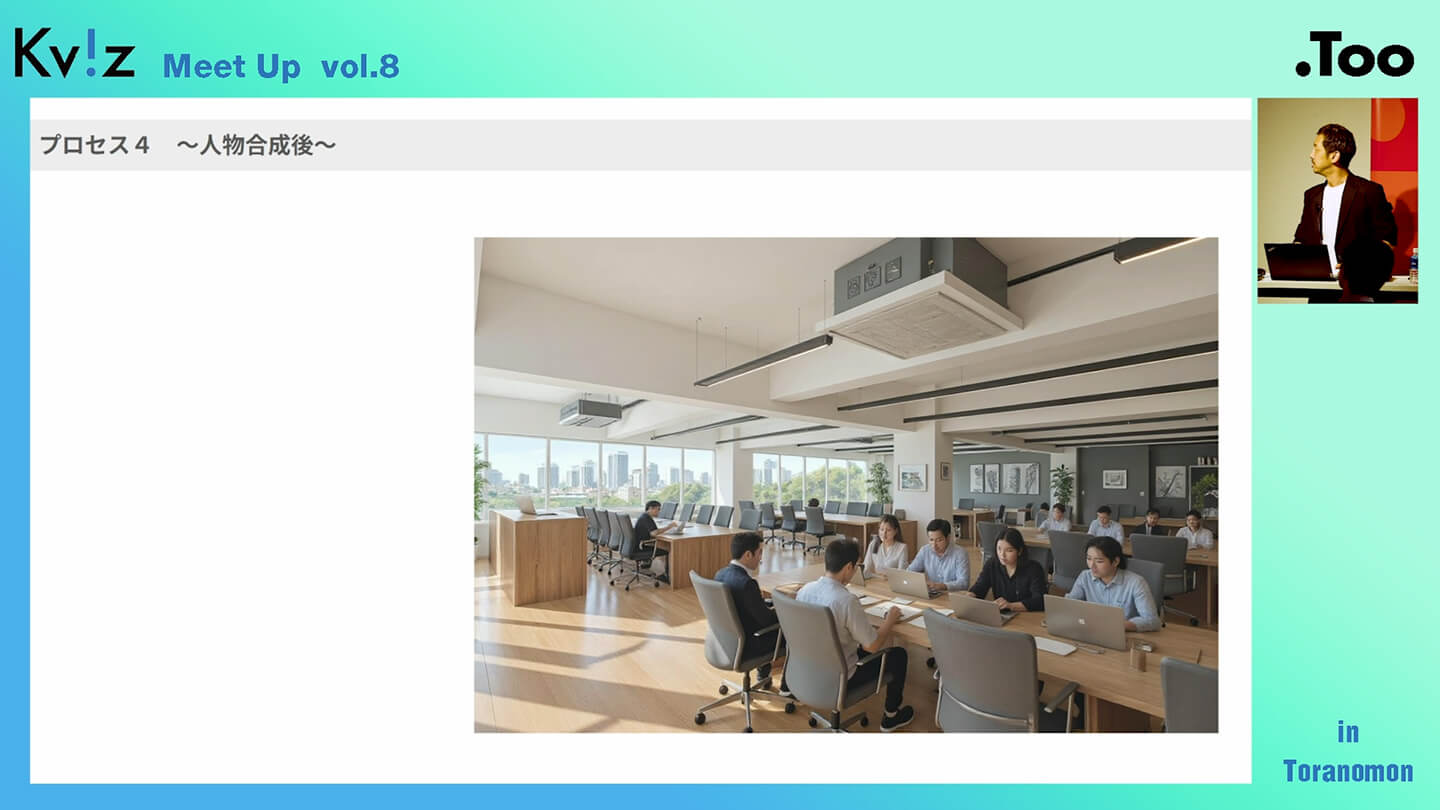
しかし、これだけだとまだ少し物足りない印象があるかもしれません。ここからさらに仕上げていくために使うのが、FLUXに搭載されている「enhance機能」です。これは、解像度を高めてビジュアルの質感を向上させるための機能で、これを使うことでディテールがぐっと引き締まり、よりリアルな表現に近づきます。
さらに、FLUXには「部分補正機能」も備わっています。たとえば「ここに人物を入れてほしい」といったピンポイントな指示を出すことで、指定した位置に人物を自動的に配置してくれるといった使い方も可能です。

この画像では人物が配置されていますが、顔がつぶれてしまっているのがわかると思います。これはなぜかというと、出力時の解像度が低いために、顔のような繊細な要素の生成がうまくいかないからです。
こうした問題を解決するために重要なのが、先ほども触れた「enhance機能」に含まれる「Upscale機能」です。この機能を使うことで、人物の顔や細部のディテールを高解像度に引き上げ、つぶれた表現を補正することができます。

こうした処理を行うことで、人物の顔もきちんと整った状態に仕上げることができます。
ツールによっては、画像全体の解像度を一括で上げるものもあります。たとえば先ほど紹介した「Project Dream」のようなサービスでは、顔だけ・人物だけに限定して解像度を上げられる機能が用意されているものもあります。必要に応じて、こういったツールを使い分けながら対応していくと良いと思います。
こうした流れに慣れると、一連の作業はおおよそ15分ほどで完了します。以前もお話ししましたが、これを従来のCG制作で再現しようとすると、かなりの時間と労力が必要になります。ただし、ここで注意が必要なのは、この画像生成プロセスは「提案段階」に適しているということです。あくまで「ざっくりとしたイメージを伝える」ための用途であり、最終的なプレゼン資料や正式なパースには不向きです。現時点では、画像の精度や正確性がそこまで高くないためです。
とはいえ、初期提案や方向性の確認といった場面では、スピード感と説得力を両立できる手法として非常に有効だと感じています。

「高級感のあるパターン」を出したい場合でも、画像生成AIを使えばこのようにすぐにビジュアルとして確認できるので、そういった場面で活用するのが効果的だと思います。
私自身、建築ビジュアライゼーションを制作する立場として、特に良いと感じているのが、クライアントからの抽象的な要望に対して視覚的に応える手段としてAIが使える点です。たとえば、「この空間、もう少し高級感がほしい」といったリクエストはよくありますが、言葉だけではなかなか具体的な雰囲気を掴めないことがあります。
そんな時に、プロンプトに「高級感を出したい」と入力して画像を生成してみると、AIは照明の質感やマテリアルの選定、色味のトーンなど、“高級感”を構成する要素をビジュアルとして提案してくれるんですね。
その結果、「なぜ今の提案では高級感が出ていないのか」が自然と見えてきて、それを参考にしながらパースやデザインに反映させることができます。この使い方は、非常に実務的で、AIならではの価値だと思っています。

Revit関連AIツール紹介

次に、Revitについても少し触れておきます。おそらく多くの方が業務で活用されているかと思いますが、「操作が複雑で扱いづらい」と感じているという声もよく耳にします。
実際、Revitは非常に強力なBIMツールである一方で、慣れていないと操作が煩雑に感じられる場面もあります。そうした中で、最近はRevitの使い勝手を大きく改善してくれるAI系のアドオンツールも登場しており、私たちもお客様に導入をおすすめすることがあります。
特におすすめなのが、『Pele AI』と『Switch』という2つのツールです。なかでもPele AIは非常にユニークな機能を備えていて、音声やテキストによる指示を通じて、BIMモデルの作成を支援してくれるアドインです。こういったツールをうまく取り入れることで、Revitの持つポテンシャルをもっと活かせるようになると思いますし、設計業務の負担もかなり軽減できるのではないかと感じています。
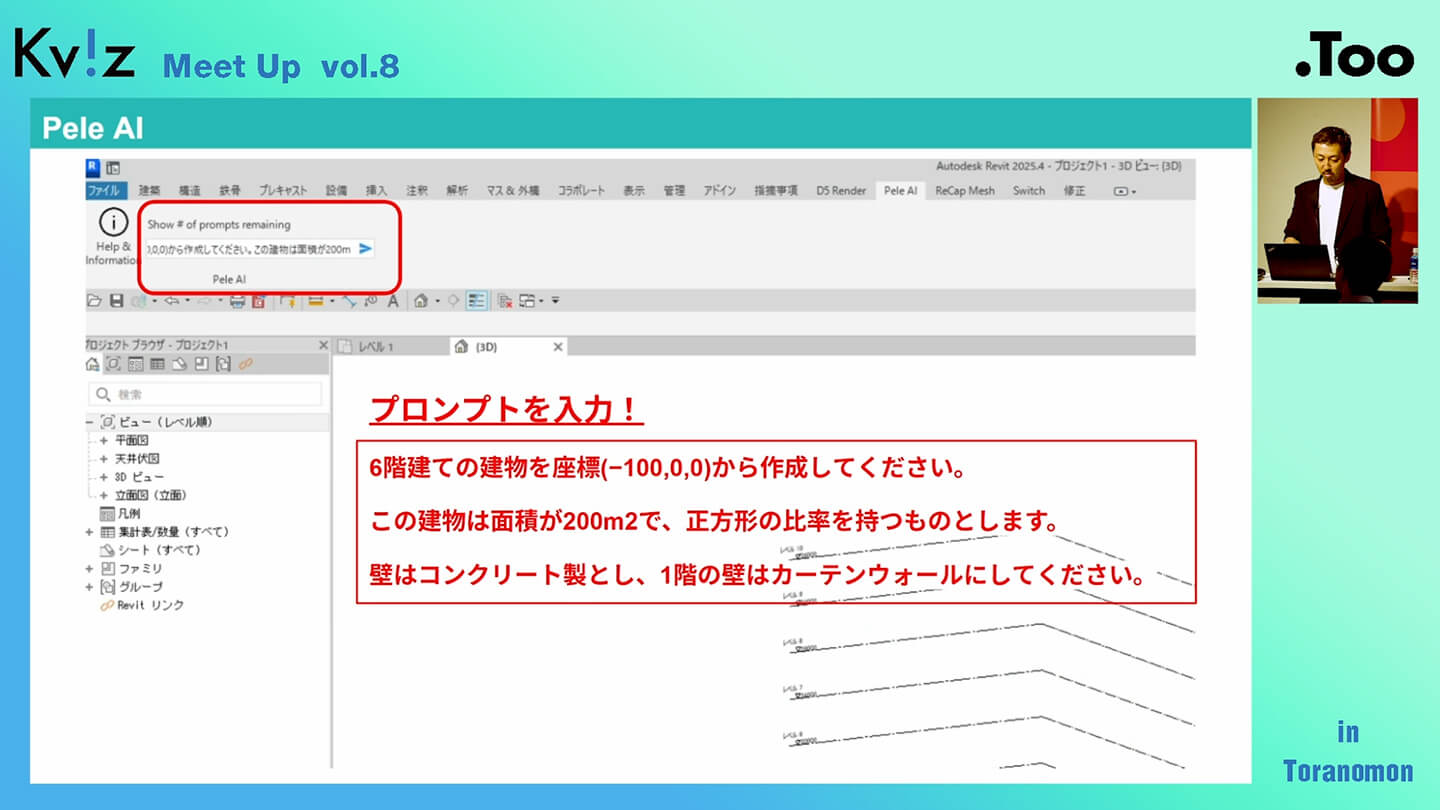
まずは、画像にある以下のプロンプトを入力します。
「6階建ての建物を座標(-100,0,0)から作成してください。この建物は面積が200m2で、正方形の比率を持つものとします。壁はコンクリート製とし、1階の壁はカーテンウォールにしてください。」
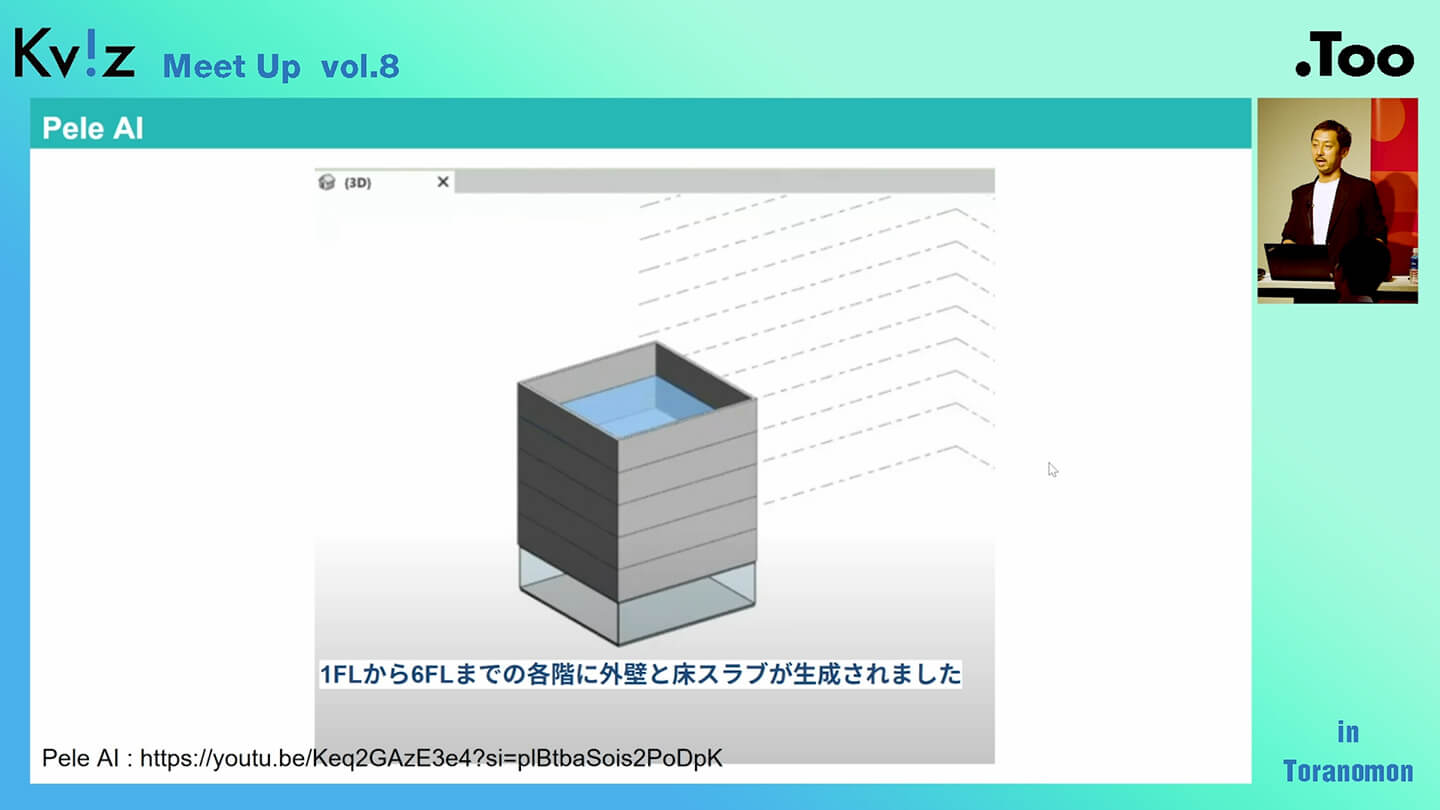
すると、このように自分で作らなくてもある程度のところまでは自動で形にしてくれるようになります。操作に慣れていなくても直感的に扱える機能が増えてきていますので、今後はぜひ積極的に活用してみてください。
また、Revitといえば「アドインがないと便利に使えない」という課題を感じている企業も多いのではないでしょうか。実際、「こういう機能があれば便利なのに」と思っても、アドインをどうやって開発会社に依頼すればいいのかわからないという声もよく聞きます。
そういった悩みに対応してくれるのが、アドイン開発のアシスタントツールです。たとえば、「こういうものを作りたい」「こんな操作を自動化したい」といった、ざっくりとした会話ベースの要望からスタートして、最終的には開発会社に渡せるレベルの要件定義まで自動でまとめてくれるような支援ツールも出てきています。

画像生成サンプル

最後に、これら7つの画像生成AIを使って、同じプロンプトを入力した場合にどのような画像が生成されるのか、建物・人物・植栽のそれぞれで比較していきます。
これまでの説明の通り、それぞれのAIには得意・不得意や特徴の違いがあり、同じ指示でもまったく異なるアウトプットが出てくることがあります。この比較を通じて、ツールごとの表現力や適性を視覚的に理解してもらえるのではないかと思います。
建物

まずはMysticからです。こちらは、シンプルなプロンプトにもかかわらず、雰囲気のある建築イメージをしっかりと描き出してくれました。

次はimagen 3です。

Imagen 4になると、バージョンアップにもかかわらず、意外にも出力の完成度が下がってしまっているように見受けられます。AIのアップデートが必ずしも画質や構成の向上に直結しないという一例です。

FLUXを使うと、建築パースに近い表現が可能になります。

Ideogram 3では、被写界深度(ピントの合う範囲)を制御しながらの生成が可能で、写真表現としてのリアリティを高めています。

一方で、OpenAI社のDALL·Eに関しては完成度はやや物足りない結果となりました。
前提として、建物の生成は画像生成AIにとって難易度が高いということです。人物であれば、目や鼻の位置など構造がある程度決まっており、AIが学習しやすいのですが、建物は形状や階数、構成が非常に多様でパターン化しづらいため、精度のばらつきが出やすいという背景があります。
人物

次は人物の生成についてです。まずMysticは、人物の描写が得意で、雰囲気のある印象的な絵を出力してくれます。

また、「高級デパートで歩くカップルを生成してください」というプロンプトに対して、男性同士のペアが描かれたのはimagen 4です。これは多様性への対応と考えると、AIの進化を感じさせる結果でもあります。

一方で、FLUXは人物になるとやや苦手な印象です。建物は得意でも、人間表現には精度の限界が見られます。

Runwayは、人物も含めて全体的に安定感があり、万能型のAIという印象です。
植栽

最後の最後に、植栽の生成についてです。Mysticは、自然なランダム性を持った植栽を描いてくれるのが特徴です。

他のモデルを見ると、どうしても植物が作り物のように見えてしまうケースが多く、リアリティにはやや欠ける印象があります。

その中で、Runwayは比較的うまく植物を描写してくれる印象がありました。質感や構成に自然さがあり、使いやすさを感じます。
このようにそれぞれのAIモデルの特徴を踏まえて、目的に応じた使い分けが重要だと感じています。

完全版の講演内容は、スペースラボ社のサイトにて公開
今回、非常にボリュームが多い講義内容となってしまったため、当セミナーレポートでは、一部のお話を省いて掲載しております。
●建築ビジュアライゼーションで使えるAIサービス3選
●AIとの付き合い方
など、いくつかのお話を追加した完全版は、追ってスペースラボ社のサイトにて公開いたします。
リンクはこちらに掲載しますので、しばし公開をお待ちください。ありがとうございました。

建築ビジュアライゼーション MeetUp第8弾 ラインナップ
- 01.3ds Max 新情報(オートデスク)
- 02.建築ビジュアライゼーションにおけるAIの活用(Chaos Software)
- 03.建築業界における画像生成AIの可能性について(スペースラボ / iceberg theory holdings) ←今ここ!
- 04.“良い絵”とは何か?写真家のまなざしから学ぶ建築ビジュアライゼーション(ナカサアンドパートナーズ)
- 「建築ビジュアライゼーション MeetUp第8弾」一覧ページ


